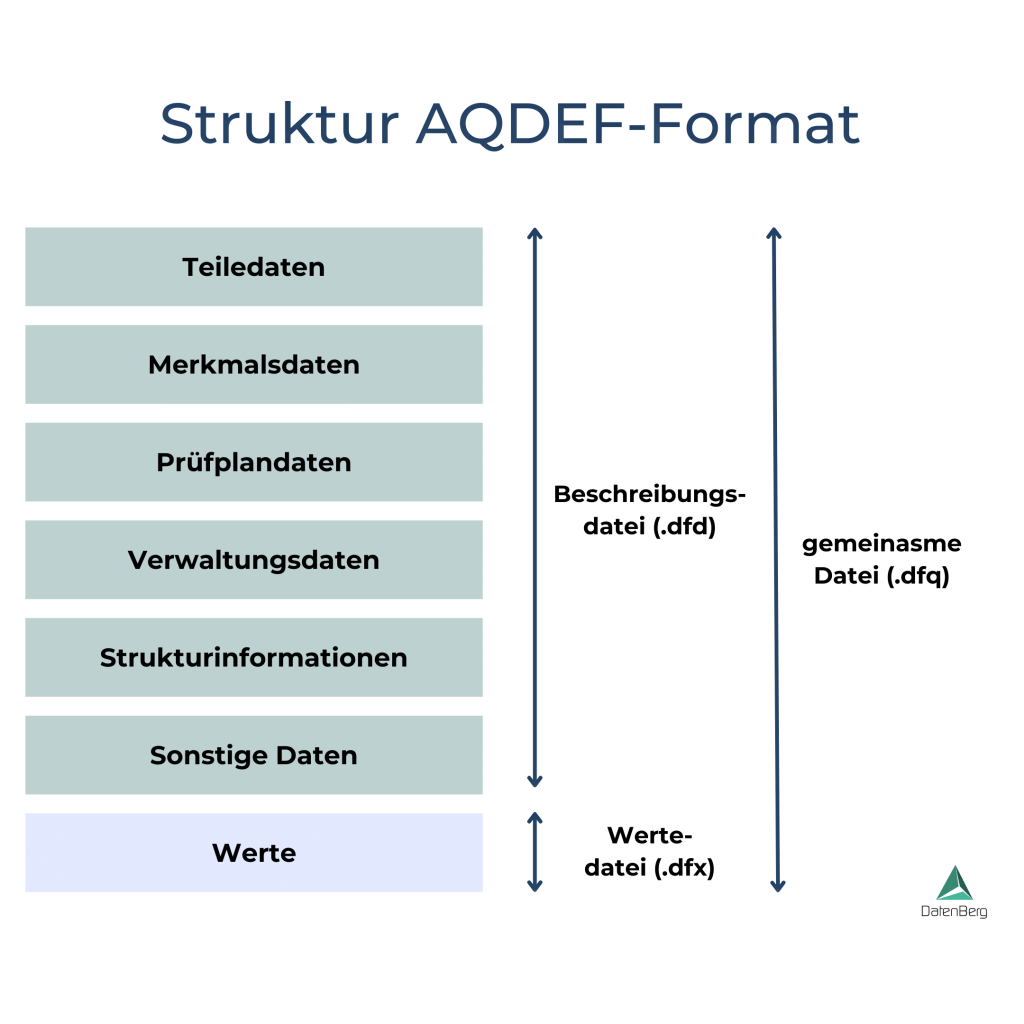
Data Historian Vergleich 2026: AVEVA, Siemens & smartPLAZA im Test
Produktionslinien liefern heute mehr Daten als Produkte. Die Kunst besteht darin, aus diesem Datenstrom echte Mehrwerte und Wettbewerbsvorteile zu generieren. Zwischen rohen Maschinendaten und echten Prozessverbesserungen klafft jedoch oft eine Lücke. Genau hier setzen Data Historian Systeme an. Sie sammeln Prozessdaten, speichern sie langfristig in einer Zeitreihendatenbank und stellen sie für Analysen und Optimierungen bereit.
Ein Data Historian ist mehr als nur ein Datenspeicher – er ist das Rückgrat moderner Produktionsdatenerfassung und bildet die Grundlage für Manufacturing Analytics, vorausschauende Wartung und kontinuierliche Prozessoptimierung.
Die vier Grundtypen von Data Historian Software
Bei der Auswahl eines Historian Systems sollten Unternehmen zunächst verstehen, welche grundlegenden Architekturen am Markt verfügbar sind:
- 1. Enterprise-Plattformen: Für Konzerne mit globalen Standorten und komplexen Integrationen. Häufig 'Cloud-First'-Strategie. Hohe Investition, lange Implementierungszeit (6-12 Monate), maximale Skalierung.
- 2. SCADA-integrierte Historian-Systeme: Eng an einen Automatisierungshersteller gebunden, ideal bei klarer Herstellerstrategie (z. B. Siemens, AVEVA, GE). Diese Data Historians profitieren von nahtloser Integration, sind aber weniger flexibel bei Multi-Vendor-Umgebungen.
- 3. Mittelstandslösungen: Fokus auf schnelle Einführung, überschaubare Kosten und Nutzung ohne große IT- oder Data-Science-Teams. Diese Data Historian Software kombiniert oft Datenerfassung mit Analytics und Qualitätsmanagement.
- 4. Eigenentwicklung: Maximale Flexibilität, aber hoher Architektur‑, Entwicklungs‑ und Wartungsaufwand sowie starkes internes IT-Know-how erforderlich. Für die meisten Unternehmen keine empfohlene Option.
Etablierte Data Historian Systeme im Überblick
AVEVA™ PI System™ (früher Osisoft)
- Positionierung: Der Industriestandard unter den Data Historian Lösungen für große Unternehmen.
- Stärken: Viele Schnittstellen, hohe Skalierbarkeit, großes Partnernetzwerk.
- Einsatz: Konzerne mit globalen Strukturen und eigener PI-Expertise.
- Herausforderungen: Hohe Lizenzkosten, lange Implementierungszeiten, dedizierte Spezialisten erforderlich.
GE Proficy Historian
- Positionierung: Proficy ist ein cloud-nativer Data Historian mit ausgeprägtem Cloud-Schwerpunkt.
- Stärken: Effiziente Datenkompression, Cloud-native Architektur, Anbindung an moderne IT-Umgebungen wie Data Lakes und Streaming-Plattformen (AWS, Azure).
- Einsatz: Betriebe mit GE-SCADA und klarer Cloud-Strategie. Besonders für Produktionsdatenerfassung über verteilte Standorte.
- Herausforderungen: Abhängigkeit vom GE-Ökosystem, Cloud-Kosten können bei großen Datenmengen steigen.
Siemens SIMATIC Process Historian
- Positionierung: Der Data Historian für die Siemens Totally Integrated Automation (TIA).
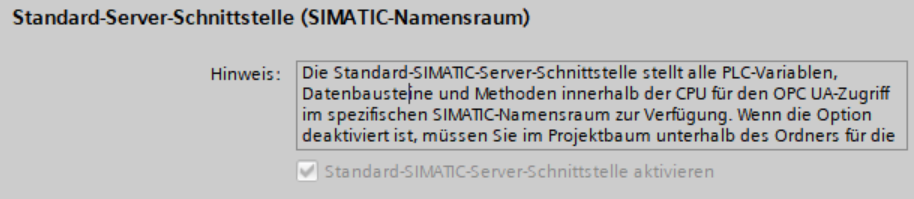
- Stärken: Sehr gute Einbettung in PCS 7, WinCC und TIA Portal, einheitliches Engineering, passende Funktionen für Prozessindustrie und regulierte Branchen (Pharma, Lebensmittel). OPC UA-Integration mit Siemens-Steuerungen.
- Einsatz: Unternehmen mit durchgängiger Siemens-Automatisierung. Besonders stark bei Brownfield-Projekten mit bestehender Siemens-Infrastruktur.
- Herausforderungen: Herstellergebunden, weniger flexibel bei Nicht-Siemens-Schnittstellen.
smartPLAZA von DatenBerg
- Positionierung: Integrierte Plattform für Data Historian, Analytics und Qualitätsmanagement speziell für den produzierenden Mittelstand, insbesondere in der Batchfertigung.
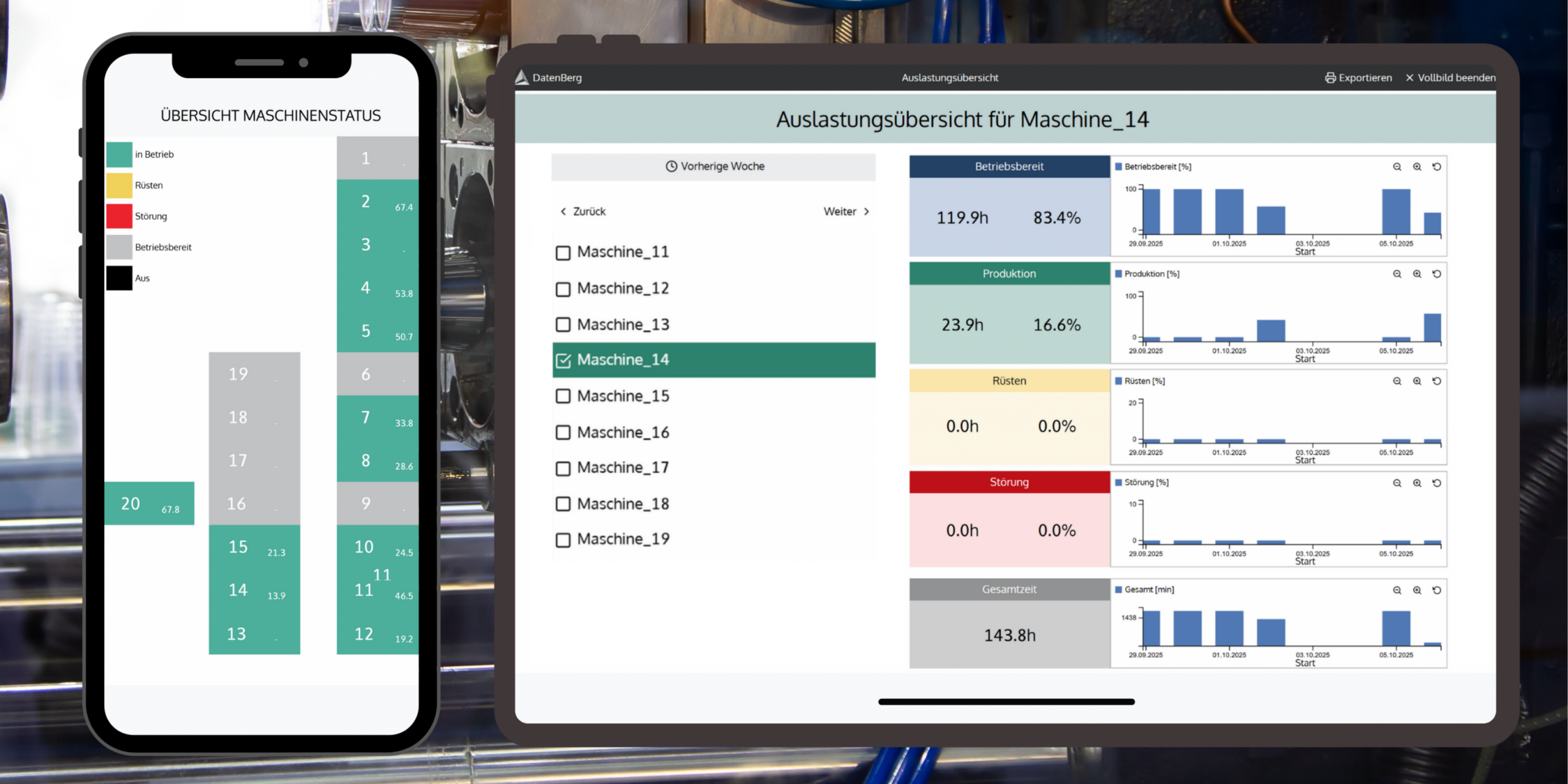
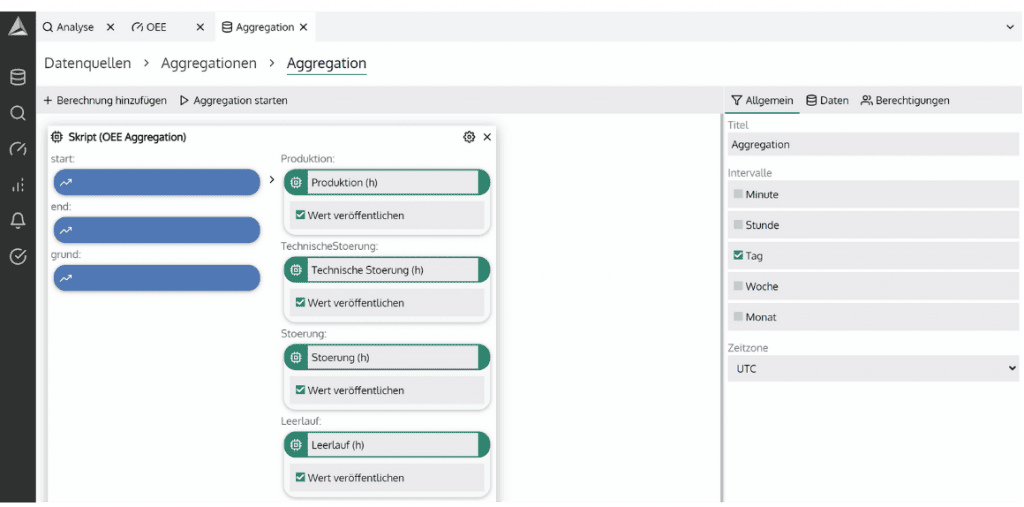
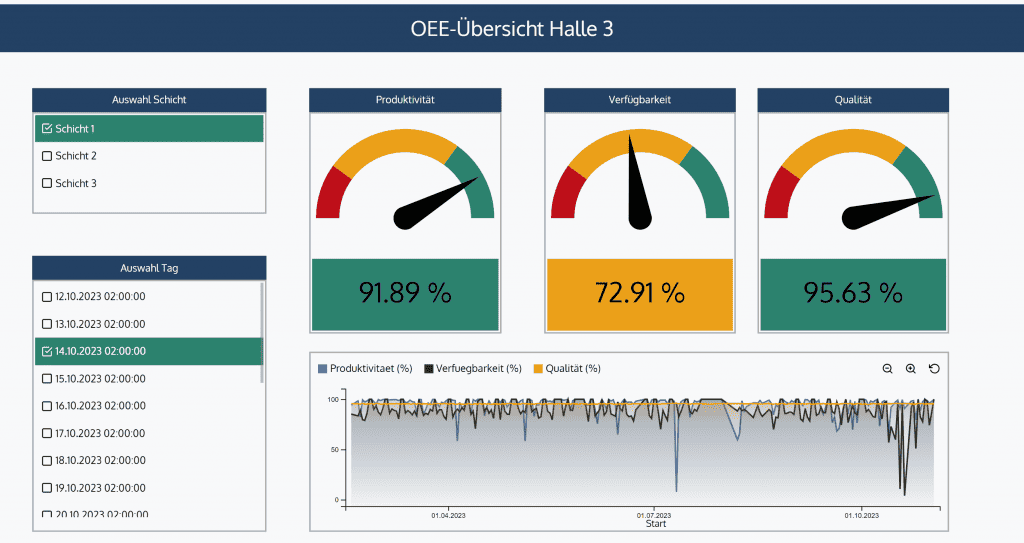
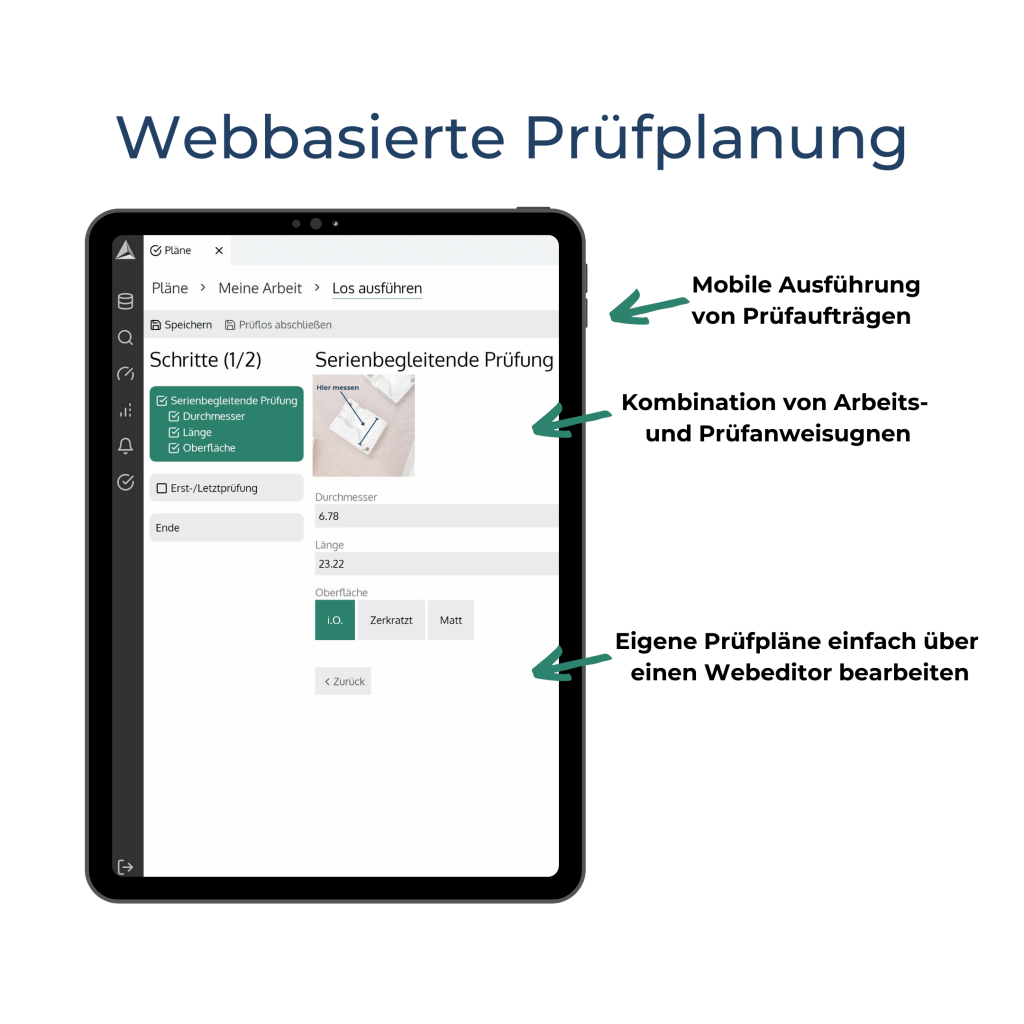
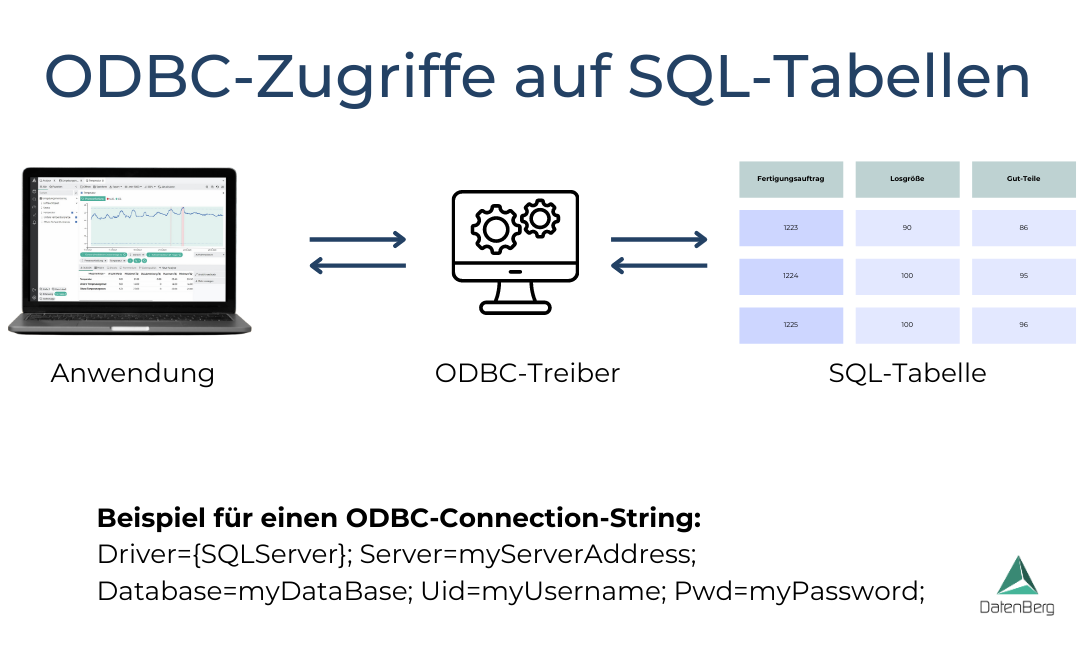
- Stärken: Standardkonnektoren (OPC UA, MQTT, REST, ODBC) für vendor-neutrale Anbindung, Integrierte Analysen inkl. KI-Unterstützung ohne Programmierung, Dashboards und digitales Schichtbuch, Papierlose Prüfpläne und SPC (Statistical Process Control), Schnelle Einführung: Produktiv in 2-4 Wochen statt 6-12 Monaten, On-Prem und Cloud-Betrieb möglich
- Einsatz: Mittelständische Produktionsbetriebe mit begrenzten IT-Ressourcen, die vendor-neutrale Anbindung und integriertes Qualitätsmanagement benötigen. Ideal für Batch-Fertigung (Pharma, Lebensmittel, Chemie).
- Herausforderungen: Weniger geeignet für Globalplayer mit 20+ Standorten und hochkomplexen, globalen Anforderungen.
Vergleichstabelle von Data Historians
| System | Stärken | Schwächen | Geeignet für | Kosten |
|---|---|---|---|---|
| AVEVA PI System | Skalierbarkeit, 450+ Schnittstellen, großes Partnernetzwerk | Hohe Kosten, lange Einführung (6-12 Monate), dedizierte Experten erforderlich | Konzerne mit globalen Standorten | €€€€ |
| Siemens SIMATIC Process Historian | TIA-Integration, regulierte Branchen, einheitliches Engineering (PCS 7, WinCC) | Herstellergebunden (Siemens-Ökosystem), weniger flexibel bei Multi-Vendor | Siemens-Umgebungen, Prozessindustrie | €€€ |
| smartPLAZA (DatenBerg) | Schnelle Einführung, KI-Analytics ohne Code, integriertes QM, vendor-neutral, On-Prem & Cloud | Weniger für Globalplayer mit > 20 Standorten | Mittelstand, Batchfertigung, begrenzte IT-Ressourcen | € |
| GE Proficy Historian | Cloud-nativ (AWS/Azure), effiziente Kompression, Data-Lake-Integration | GE-spezifisch, Cloud-Abhängigkeit, variable Kosten | Betriebe mit GE-SCADA und Cloud-Strategie | €€€ |
Moderne Mittelstandsansätze: Vom Datenspeicher zur Produktionsanalyse
Klassische Historian-Systeme sind in erster Linie Datenspeicher mit Visualisierung: Sie erfassen und archivieren Prozessdaten zuverlässig in einer Zeitreihendatenbank, überlassen tiefere Analysen und Qualitätsmanagement aber meist externen Tools oder Spezialisten.
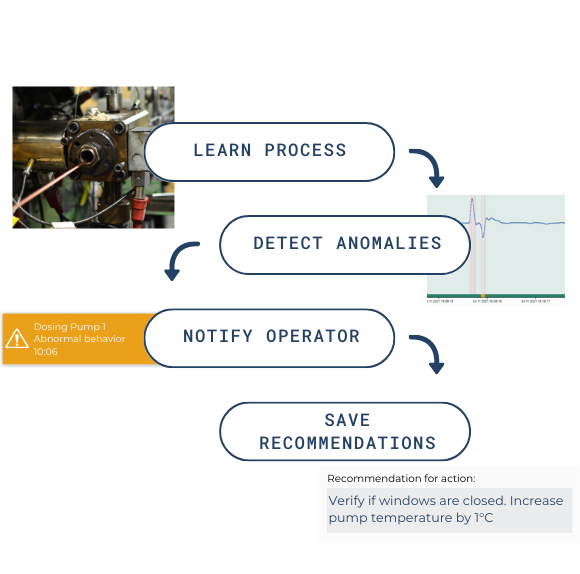
Modernere Data Historian Software für den Mittelstand, wie die smartPLAZA, gehen weiter und kombinieren:
- Historian-Funktionalität mit Standardkonnektoren (OPC UA, MQTT, REST, ODBC)
- Integrierte Analysewerkzeuge ohne Programmierung
- Vorhersagewerkzeuge mit KI-Unterstützung
- Aussagekräftige Dashboards für den operativen Alltag
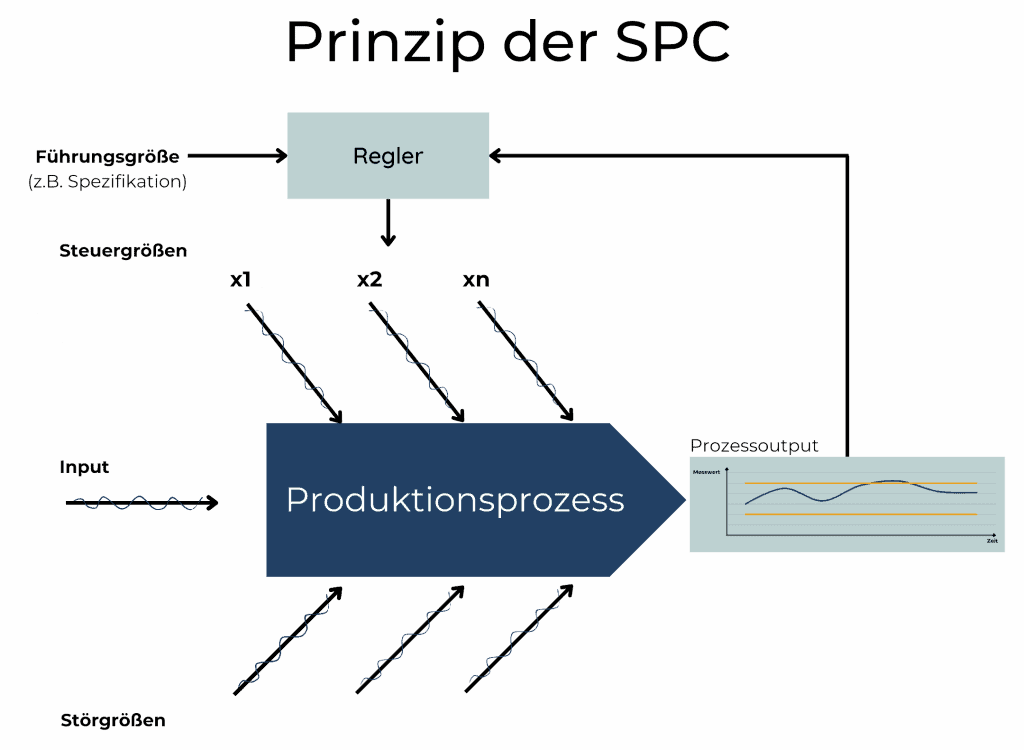
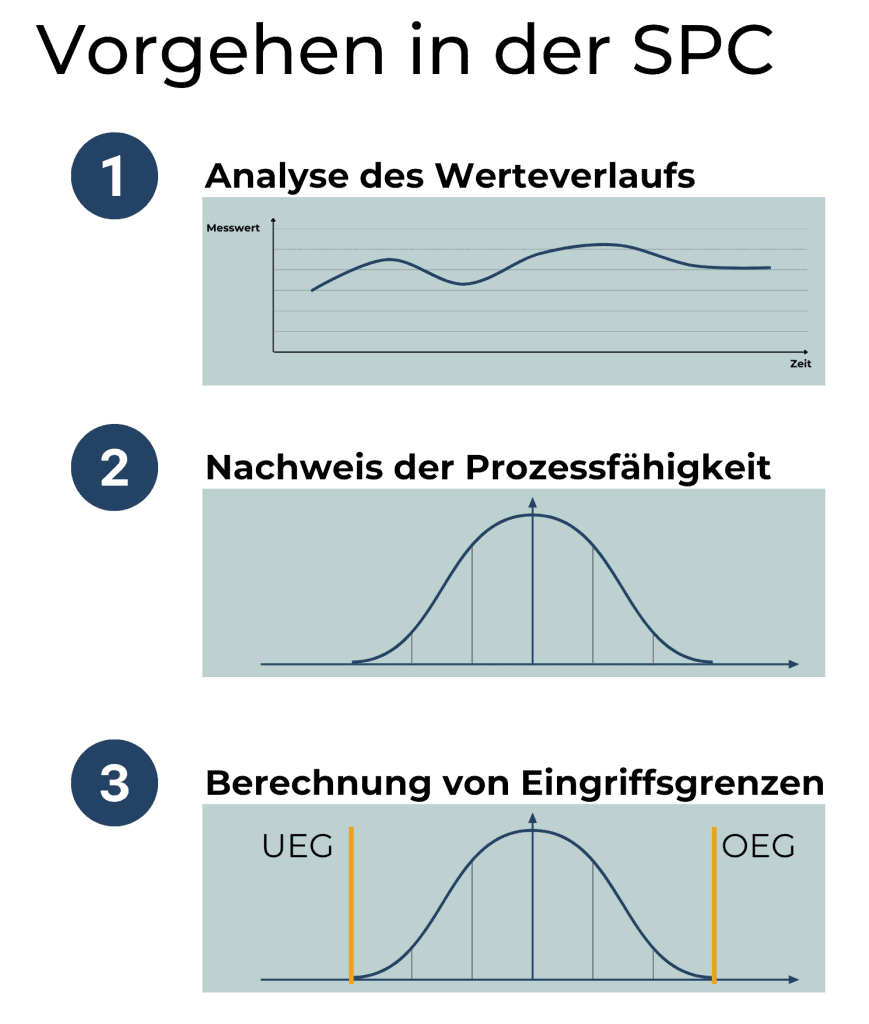
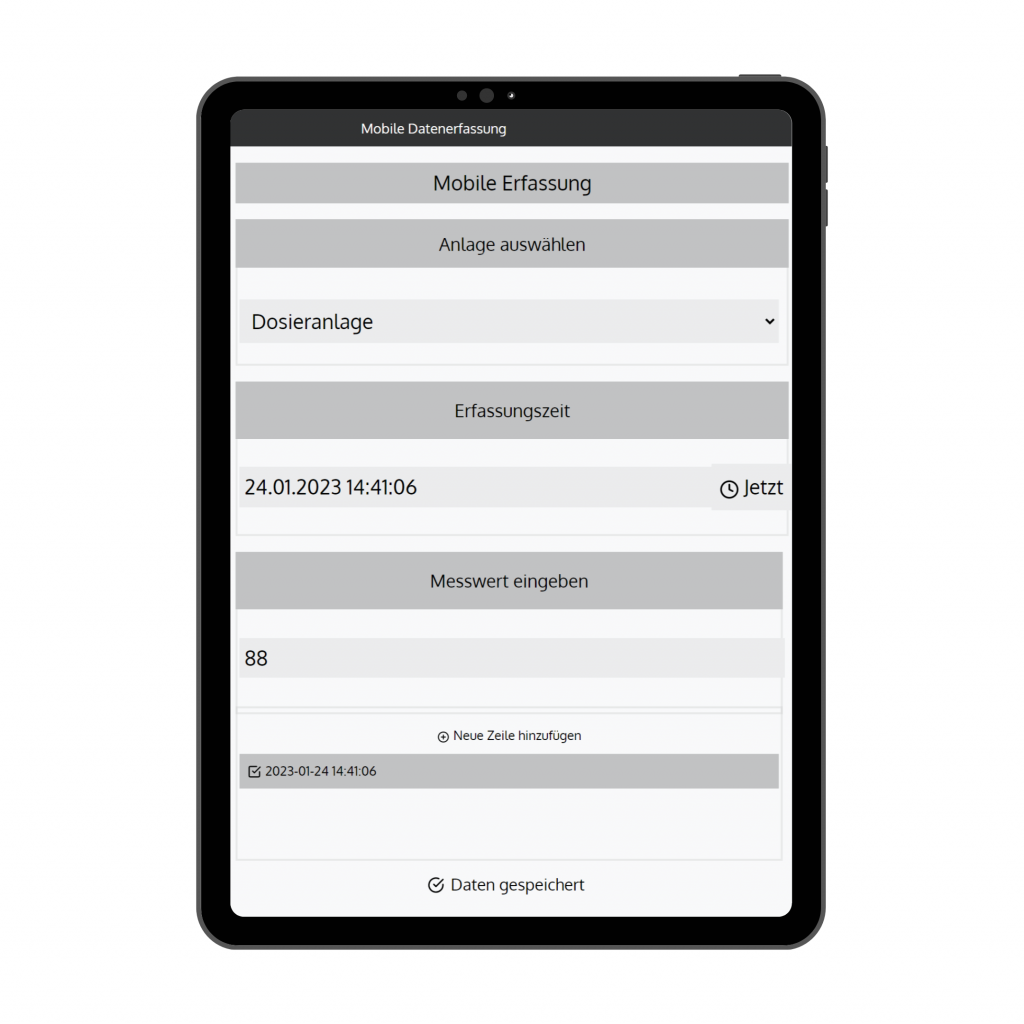
- Funktionen fürs Qualitätsmanagement (SPC, Prüfpläne, papierlose Dokumentation)
Dadurch lassen sich typische Use Cases – etwa Ursachenanalysen bei Prozessabweichungen, prädiktive Qualitätsprognosen oder Audit-Trails – direkt in einem System abbilden, ohne den Umweg über Excel-Exporte, externe BI-Tools oder zusätzliche QMS-Software nehmen zu müssen.
Wann ist eine Mittelstandslösung die richtige Wahl?
Wenn eine Lösung benötigt wird, die:
- In wenigen Wochen produktiv ist (statt in Monaten)
- Ohne eigenes Data-Science-Team auskommt
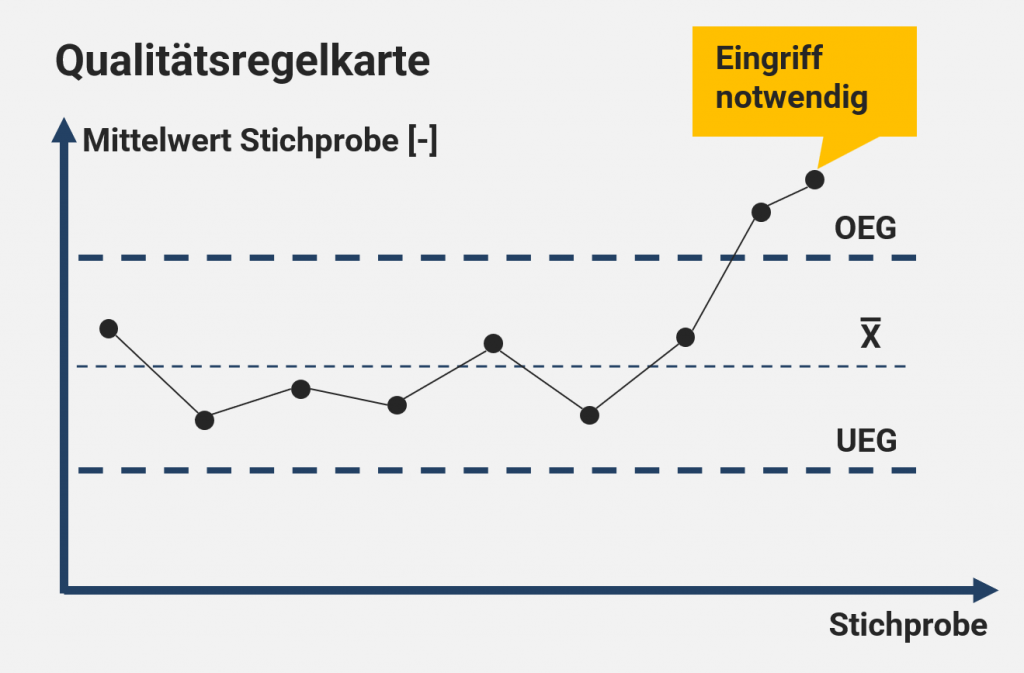
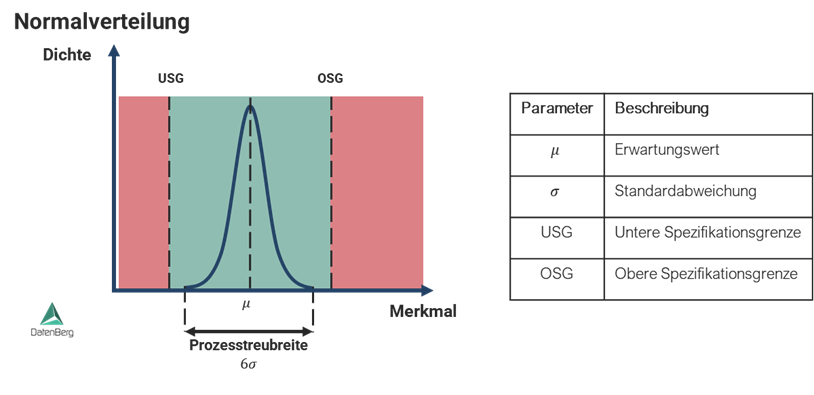
- Analytics und Qualitätsmanagement (z. B. SPC, Prüfpläne, papierlose Dokumentation) direkt integriert
- Vendor-neutral an bestehende Anlagen angebunden werden kann
- Mit On-Prem und Cloud flexible Betriebsmodelle bietet
...dann eignet sich eine Lösung wie smartPLAZA optimal.
Gerade im Mittelstand ist ein Data Historian, der schnell eingeführt und breit genutzt wird, häufig wertvoller als eine hochkomplexe Enterprise-Plattform, die viel Budget bindet und im Alltag nur teilweise ausgeschöpft wird.
Data Historian Vergleich im Unternehmen durchführen
Wie funktioniert der Data Historian Vergleich in der Praxis? Wir haben die wichtigsten Schritte zusammengefasst:
1. Anforderungen klären
Konkrete Use Cases definieren: Welche Prozessdaten sollen erfasst werden? Standorte, vorhandene Automatisierungssysteme (OPC UA, MQTT?), Nutzergruppen, Budgetrahmen und Zeithorizont festlegen.
Typische Fragen:
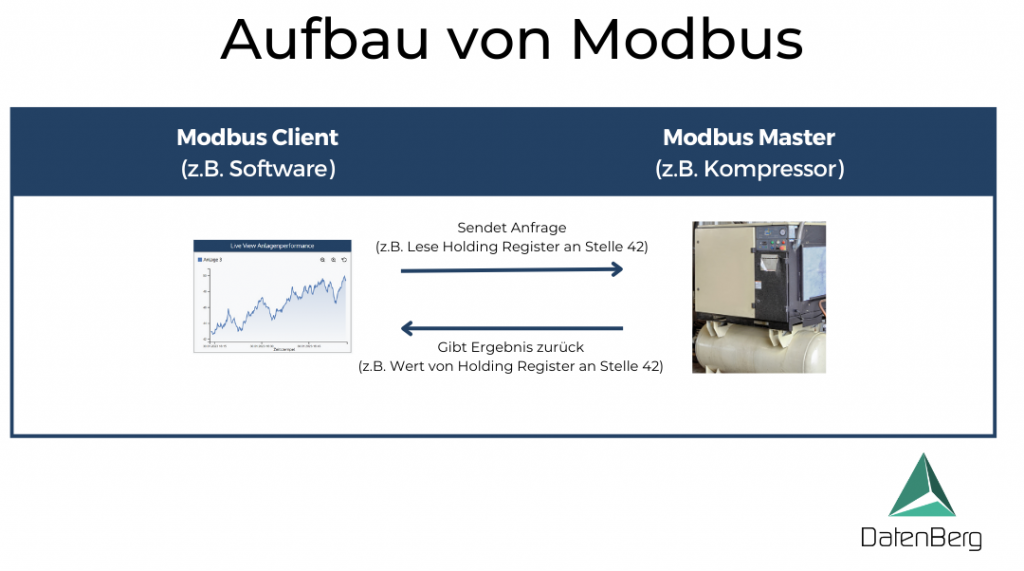
Benötigen wir nur Maschinendatenerfassung oder gibt es auch Anforderungen aus dem Qualitätsmanagement abzudecken (z.B. SPC)? Soll der Historian on-premise oder cloud-basiert betrieben werden? Wie viele Datenpunkte müssen erfasst werden? Welche Schnittstellen sind erforderlich (OPC UA, Modbus, MQTT, REST)?
2. Vorauswahl treffen
2–3 passende Historian Systeme shortlisten – idealerweise abgestimmt auf vorhandene SCADA-/Automatisierungslandschaft und IT-Strategie.
Entscheidungskriterien:
- Vendor-Lock-in vs. Multi-Vendor-Fähigkeit
- Inhouse-Betrieb vs. Cloud
- Schnelligkeit der Implementierung
- Verfügbarkeit von Fachkräften
3. Proof of Concept durchführen
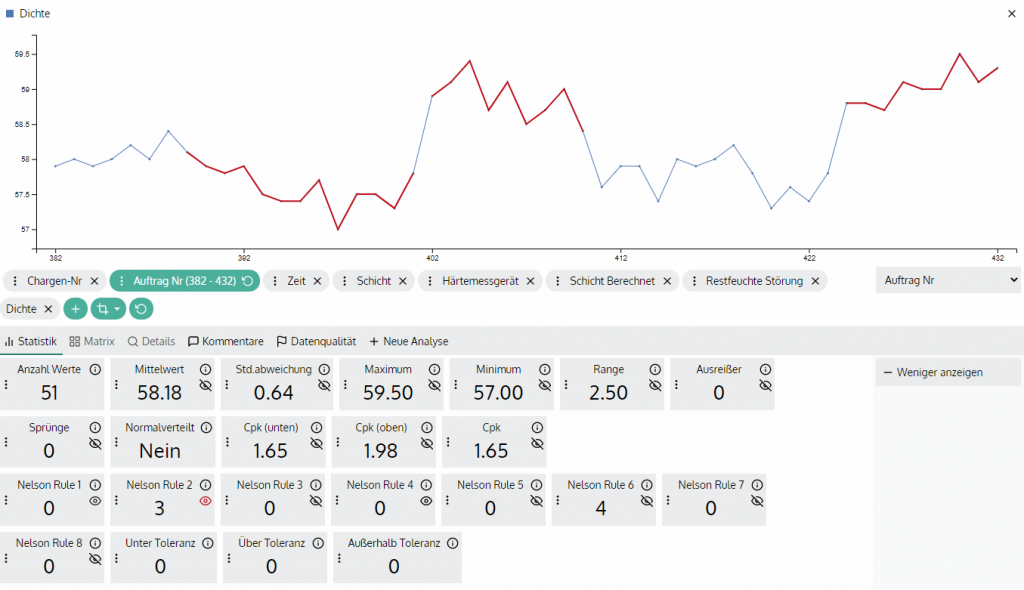
Mit echten Produktionsdaten testen, typische Anwendungsfälle durchspielen und prüfen, ob das Team das Data Historian System im Alltag selbst bedienen kann.
Testszenarien:
- Ursachenanalyse bei Prozessabweichungen
- Dashboard-Erstellung ohne IT-Abteilung
- Integration mit bestehenden Systemen (MES, ERP, SCADA)
- Prüfplan-Digitalisierung (bei QM-Anforderungen)
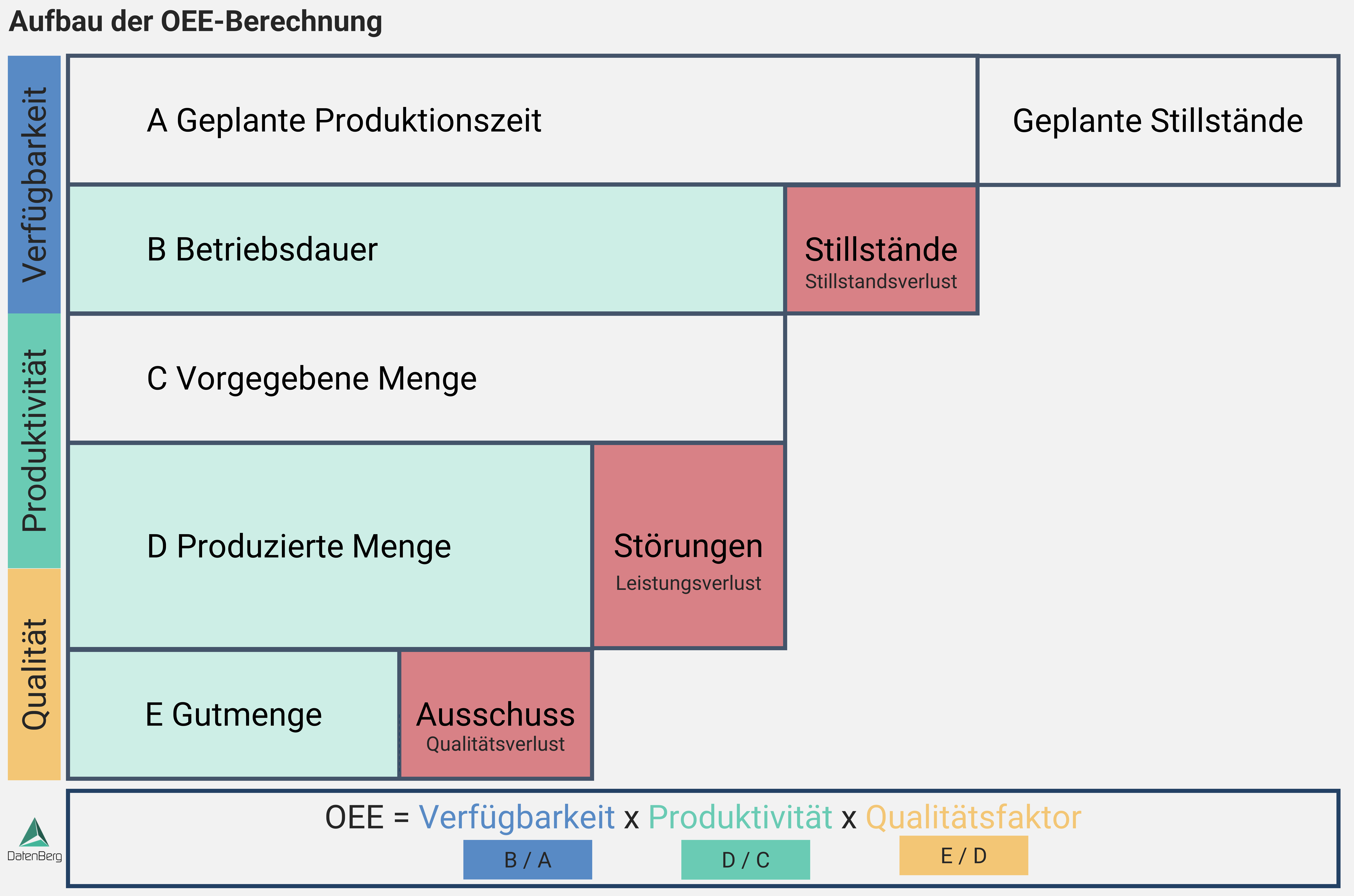
4. TCO über 5 Jahre betrachten
Nicht nur Lizenzkosten ansehen, sondern auch Gesamtkosten (Total Cost of Ownership):
- Implementierung (Berater, Schnittstellen, Schulung)
- Betrieb (Personal, Wartung, Updates)
- Zeit bis zum ersten messbaren Nutzen (Time-to-Value)
Faustregel: Ein Data Historian, der nach 3 Monaten produktive Ergebnisse liefert, ist oft wirtschaftlicher als ein System, das nach 12 Monaten 20% mehr Funktionen bietet.
5. Team einbinden
Entscheidend ist, dass Produktion, Qualitätssicherung und IT die Lösung akzeptieren und nutzen – nicht allein das Feature-Sheet.
Best Practice: Pilotprojekt in einer Produktionslinie starten, Feedback einholen, dann skalieren.
Fazit: Der richtige Data Historian für Ihre Anforderungen
Die Wahl des passenden Data Historian Systems hängt stark von Unternehmensgröße, IT-Strategie und Automatisierungslandschaft ab:
- AVEVA PI System → Für Konzerne mit globalen Standorten und PI-Expertise
- Siemens SIMATIC Process Historian → Bei durchgängiger Siemens-Automatisierung
- GE Proficy Historian → Für Cloud-First-Strategien mit GE-SCADA
- smartPLAZA → Für Mittelstand mit Fokus auf schnelle Einführung, integriertes QM und vendor-neutrale Anbindung
Der Trend geht klar in Richtung integrierter Plattformen, die nicht nur Prozessdaten speichern, sondern direkt Analytics, KI-Prognosen und Qualitätsmanagement mitbringen – ohne dass Daten zwischen verschiedenen Systemen hin- und herkopiert werden müssen.
Tipp: Starten Sie mit einem fokussierten Pilotprojekt, statt gleich die gesamte Produktion umzustellen. So minimieren Sie Risiken und können die Data Historian Software in der Praxis testen.
Über den Autor: Maximilian Backenstos ist Experte für Produktionsdatenerfassung und Industrial Analytics bei DatenBerg GmbH.
Weitere Ressourcen:
- smartPLAZA Produktübersicht: https://datenberg.eu/produkt/
- Anwendungsbeispiele für Data Historians: https://datenberg.eu/anwendungen/
- Kontakt für individuelle Beratung: https://datenberg.eu/kontakt/
Q&A
Ein Data Historian ist eine spezialisierte Datenbank-Software für die Industrie, die Maschinendaten wie Temperatur, Druck oder Durchfluss kontinuierlich erfasst, zeitgestempelt speichert und für spätere Analysen bereitstellt. Im Gegensatz zu normalen Datenbanken ist ein Historian extrem effizient in der Kompression von Milliarden Datenpunkten und speziell für Prozessdaten optimiert. Er ermöglicht die langfristige Aufbewahrung über Jahre bis Jahrzehnte und schnelle Abfragen über große Zeiträume.
Eine typische Anwendung: Eine Produktionsanlage sendet jede Sekunde tausende Messwerte, der Historian speichert diese und ermöglicht später die Analyse von Fragen wie "Warum war die Qualität am 15. Januar um 14:30 Uhr schlecht?" Kurz gesagt ist ein Data Historian das Langzeitgedächtnis einer Produktionsanlage, das hilft, Prozesse zu verstehen, zu optimieren und Fehlerursachen nachzuvollziehen.
Die Kosten variieren stark je nach System: Mittelstandslösungen wie smartPLAZA starten im unteren fünfstelligen Bereich pro Jahr und sind in wenigen Wochen produktiv. Enterprise-Lösungen liegen häufig bei über 100.000 € und benötigen 6-12 Monate für die Implementierung. Bei der Kalkulation sollten Sie nicht nur Lizenzkosten berücksichtigen, sondern auch Implementierung, Schulung, Wartung und interne Personalkosten über einen 5-Jahres-Zeitraum betrachten.
Das hängt vom gewählten System ab. Klassische Enterprise-Historian-Systeme erfordern oft spezialisierte Fachkräfte für Datenanalyse und Programmierung. Moderne Mittelstandslösungen wie smartPLAZA bieten jedoch integrierte Analyse-Tools mit vorgefertigten Dashboards, KI-Unterstützung und No-Code-Konfiguration, sodass Produktionsmitarbeiter und Qualitätstechniker das System ohne Programmierkenntnisse nutzen können. Für einfache Anwendungsfälle wie Trendanalysen oder SPC reichen in der Regel Schulungen von 1-2 Tagen aus.