Eine SQL-Tabellen verwaltet Daten in einer strukturierten Form. Dafür werden relationale Datenbanken wie zum Beispiel PostgreSQL verwendet. Die Tabellen bestehen aus Zeilen und Spalten, wobei jede Zeile einen Datensatz und jede Spalte eine gewisse Datenkategorie (z.B. Ganzzahl, Text, Datum) beinhaltet. Diese Tabellen sind nach einem vordefinierten Schema organisiert, das die Art der gespeicherten Daten festlegt. Mit Hilfe von SQL (Structured Query Language) können Abfragen erstellt werden, um Daten zu suchen, hinzuzufügen, zu ändern oder zu löschen. Primärschlüssel dienen als eindeutige Identifikatoren für Zeilen, während Fremdschlüssel Beziehungen zwischen verschiedenen Tabellen herstellen können. Dies ermöglicht komplexe Abfragen, Berichte und Analysen. Insbesondere ist der Zugriff durch weitere Systeme zur Weiterverarbeitung möglich. Die Abfragesprache SQL ist standardisiert, einzelne Anbieter von Datenbanksystemen implementieren den Standard verschieden.
Es gibt verschiedene Anbieter von SQL-Datenbanken. Von Open-Source Software wie die PostgreSQL zu kommerziellen Anbietern wie Oracle. Unterschiede existieren bei Themen wie Lizenzierung, unterstützten Datentypen und Betriebssystemen.

Doch wie sieht der Aufbau einer SQL-Abfrage konkret aus? Eine SQL-Abfrage besteht aus den folgenden Hauptkomponenten:
SQL stellt eine große Anzahl von Funktionen zur Verfügung, die in komplexeren Abfragen zum Einsatz kommen können. Die genaue Syntax und Verwendung kann je nach verwendetem Datenbankmanagementsystem leicht variieren.
Nehmen wir das obige Beispiel: Eine Tabelle mit den Spalten Produktionsauftrag, Losgröße und Gutteile. Die Abfrage könnte wie folgt aussehen, um die Zeilen auszuwählen, für die die Anzahl der Gutteile größer als die Losgröße ist:
SELECT Fertigungsauftrag, Losgröße, Gut-Teile
FROM Fertigungsdaten
WHERE Gutteile > Losgröße;
Diese Abfrage gibt alle Zeilen zurück, in denen die Anzahl der Gutteile größer als die Losgröße ist. Dazu gibt die Abfrage die Spalten Fertigungsauftrag, Losgröße und Gut-Teile zurück.
SQL-Tabellen können in verschiedenen Systemen und Anlagen in der Produktion entstehen. Spannend ist es, wie kann darauf zugegriffen werden? Wir haben die drei großen Kategorien IT-Systeme, Anlagen und Schatten-IT bewertet.
Nahezu alle IT-Systeme wie ERP, CAQ, MES oder SCADA arbeiten im Hintergrund mit SQL-Tabellen. Häufig hat die hauseigene IT bereits Erfahrung mit Datenzugriffen auf diese Systeme und kann diese selbst erstellen. Aus unserer Erfahrung bringt der Großteil der Hersteller auch die Offenheit für einen Austausch der Daten mit beziehungsweise bietet hierfür Lizenzbausteine an.
Einzelne Anlagen oder Prüfmaschinen können auch eine SQL-Tabelle zur Datenspeicherung verwenden. Insbesondere bei komplexeren Anlagen mit eigenem Rechner ist oft eine eigene Datenbank enthalten. Für den Zugriff ist oft eine Absprache mit dem Anlagenhersteller notwendig bzw. empfehlenswert. Bei einer Integration kann eine separate Lizenz für den Datenzugriff erforderlich sein.
Eine weitere Quelle ist die sogenannte Schatten-IT. Selbstgestrickte und historisch gewachsene Tabellen, die nicht direkt von der IT freigegeben wurden. Ein Beispiel sind Datenbanken, die mit Microsoft Access verwaltet und gefüllt werden. Hier fallen zwar keine Lizenzkosten für den Zugriff an, aber die Systeme sollten gut verstanden und dokumentiert sein, um einen stabilen Datenabruf zu gewährleisten. Natürlich existieren auch genug Anwendungen, die erfolgreich auf MS Access aufbauen und nicht zur Schatten-IT zählen, dies ist nur als illustratives - aber reales - Beispiel gedacht.
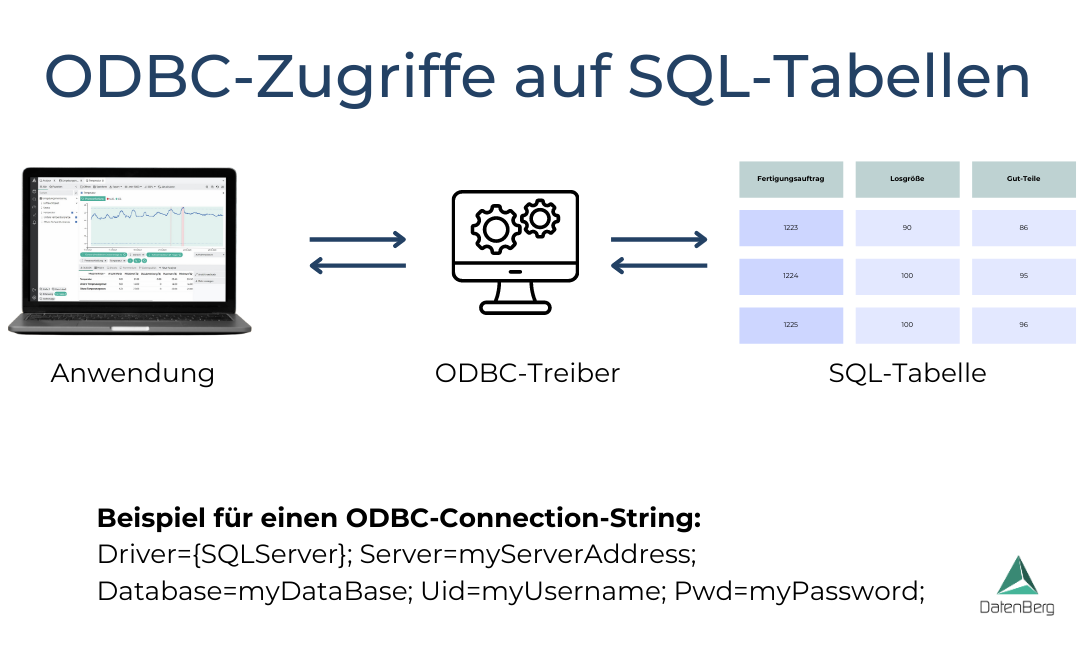
ODBC (Open Database Connectivity) ist eine standardisierte Schnittstelle, die den Zugriff auf Datenbanken unabhängig von der zugrunde liegenden Datenbanktechnologie ermöglicht. Die Schnittstelle fungiert als Brücke zwischen Anwendungen und Datenbanken, indem es eine einheitliche Kommunikationsmethode bereitstellt. Dies geschieht über ODBC-Treiber, der für jede Datenbank spezifisch implementiert ist. Mit einem Treiber und einem datenbankspezifischen ODBC-Connection-String kann auf die Daten zugegriffen werden. Auf dieser Website sind typische Verbindungsstrings gelistet.
Die Verwendung von ODBC bietet Vorteile wie leichte Anbindung, da Anwendungen nicht direkt an eine bestimmte Datenbank gebunden sind, sondern über den Treiber kommunizieren. Dies erleichtert den Wechsel zwischen verschiedenen Datenbanken. Daneben ist eine hohe Stabilität gegeben. ODBC unterstützt ebenfalls eine Vielzahl von Datenbankmanagementsystemen.
Um eine Verbindung über ODBC herzustellen, muss eine Anwendung den entsprechenden ODBC-Treiber installieren und konfigurieren. Dies beinhaltet die Definition von Datenquellen (Data Sources), die die Verbindungsinformationen enthalten. Danach kann die Anwendung über ODBC SQL-Abfragen an die Datenbank senden und Ergebnisse empfangen.
Bei der Compoundierung von Kautschukmischungen besteht die dringende Notwendigkeit, Maschinen- und Labordaten in Echtzeit zu erfassen, zu verarbeiten und zu verwalten. Diese Daten sind für die Überwachung der Produktionsprozesse, die Qualitätskontrolle und die schnelle Reaktion auf Qualitätsschwankungen von entscheidender Bedeutung. Da die Überwachung in Echtzeit kritisch ist, stellt sich die Frage, wie eine effiziente Erfassung und Verarbeitung realisierbar ist.
Herausforderungen sind dabei die Echtzeitfähigkeit, die permanente Speicherung der Daten sowie die Flexibilität, neue Datenpunkte (z.B. Sensoren) einfach in die Infrastruktur zu integrieren.
Um das Problem der Echtzeitdatenverwaltung in der Gummimischtechnik zu lösen, bietet sich eine sorgfältig strukturierte SQL-Datenbank an. Für Maschinen- und Labordaten ist jeweils eine Tabelle zu definieren. Dadurch findet eine Trennung der verschiedenen Datentypen statt und die Datenstruktur ist optimiert. Die Befüllung der SQL-Tabellen findet durch ein Transferskript aus der Steuerung statt.
Die Konsolidierung und Auswertung dieser Daten erfolgt dann über eine ODBC-Schnittstelle in der Software DatenBerg SmartPlaza im Data Warehouse. Über diese Schnittstelle werden die Daten aus den verschiedenen Tabellen gesammelt und in einer zentralen Plattform zusammengeführt. Hier finden Vergleiche der Daten und Analysen statt. Über einen Knopfdruck wird ein definierter Berichten ausgegeben.
Die Implementierung dieser Lösung bietet zahlreiche Vorteile. Durch die Verwendung von getrennten SQL-Tabellen für Maschinendaten und Labordaten kann bei Ausfall eines Systems (Recorder, Maschinendaten, Prüfmittel) das andere System die Daten weiter aufzeichnen. Auch Änderungen des Schemas (z.B. zusätzliche Prüfmerkmale) sind leicht umsetzbar.
Die Datenkonsolidierung und -analyse in DatenBerg SmartPlaza ermöglicht eine umfassende Überwachung und Steuerung der Produktionsprozesse. Qualitätsschwankungen sind so bis auf Einzelwerte zurückverfolgbar und Reaktionen sind unmittelbar ableitbar.
Durch die Entkopplung der Tabellen sind die Maschinendaten bereits drei Sekunden nach Produktionsende im Auswertesystem smartPLAZA sichtbar. Dies ermöglicht eine Überwachung nahezu in Echtzeit und ein sofortiges Eingreifen bei Abweichungen oder Problemen.
Die gewählte Lösung ermöglicht auch einen Handshake zwischen den verschiedenen Systemen. Dabei schreibt das Lesesystem in der Herkunftstabelle in einer definierten Spalte (z.B. „Handshake“) z.B. eine „0“ in eine „1“. Mit einem definierten Job können in der Herkunftstabelle alle Zeilen mit einer „1“ in der Spalte „Handshake“ gelöscht werden, da diese bereits vom Folgesystem gelesen wurden.
Insgesamt führt diese Lösung zu einer effizienten und zuverlässigen Produktionsüberwachung in Echtzeit, ermöglicht die schnelle Erkennung und Behebung von Qualitätsproblemen und trägt zur kontinuierlichen Verbesserung der Prozesse in der Gummimischanlage bei.
SQL-Datenbanken bieten einen strukturierten Aufbau. Wenn Daten einmal in eine Tabelle weggeschrieben werden, können diese einfach abgelesen werden. Damit kann ein stabiler Austausch zwischen Systemen ermöglicht werden. Somit eignen sich die Datenbanken sowohl für den Transfer zwischen Systemen bzw. Geräten, jedoch auch für einen historischen Speicher. Die Tabellen wollen jedoch gefüttert werden. Hierzu bedarf es wiederum anderer, maschinennäheren Schnittstellen wie zum Beispiel OPC UA oder Modbus.


