Bevor eine Pipeline Vorhersagen liefern kann, muss sie zunächst auf historischen Prozessdaten trainiert werden – das Modell lernt dabei den Zusammenhang zwischen Inputs und Zielwerten. Anschließend läuft die Pipeline im Live-Betrieb und wendet das trainierte Modell auf neue einlaufende Daten an (Inferenz).
Je nach Ziel stehen drei Betriebsmodi zur Verfügung, über die dieser Prozess gesteuert wird.
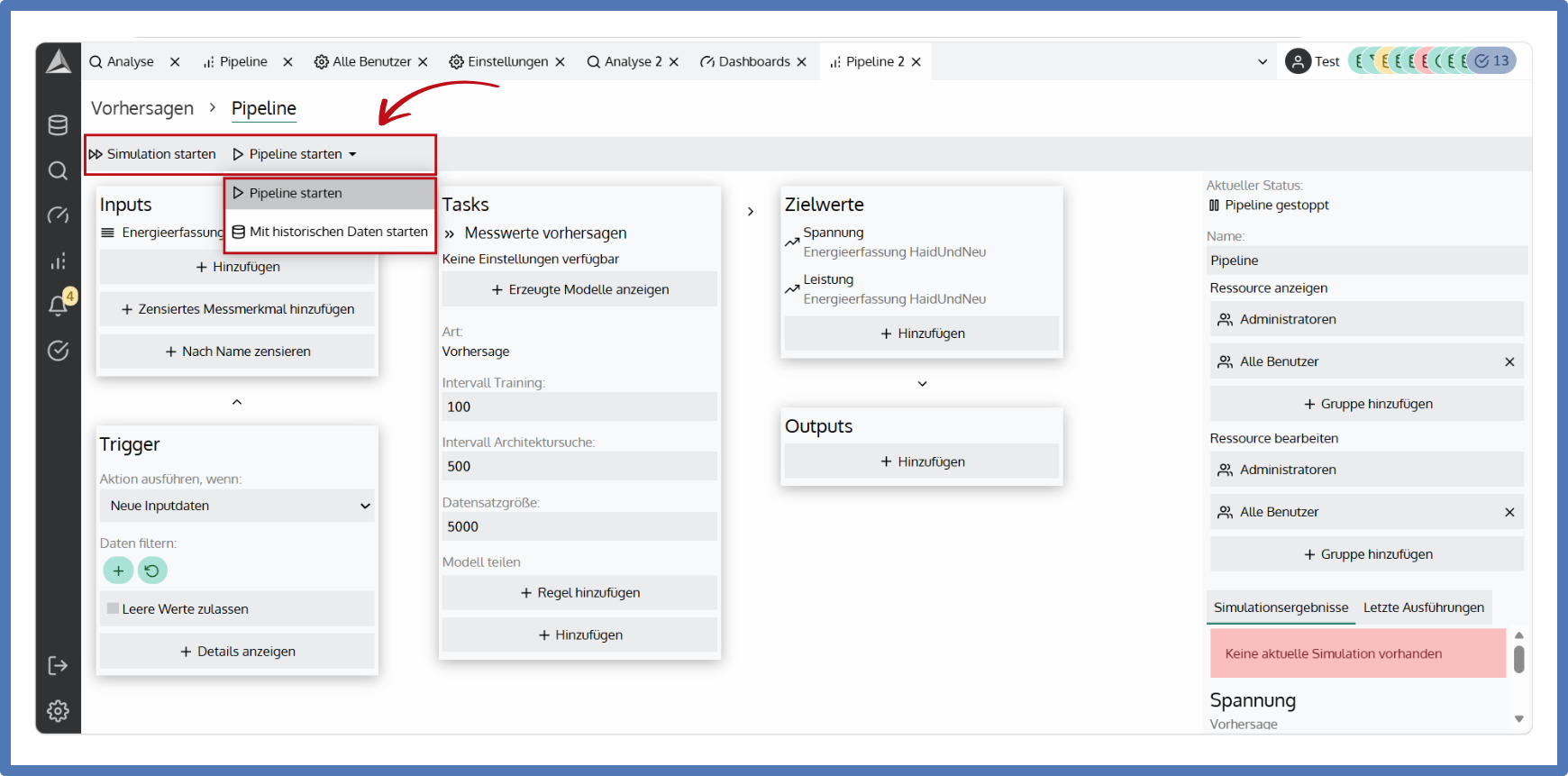
Betriebsmodi einer Pipeline
Der gewünschte Betriebsmodus wird in der Pipeline-Übersicht gestartet.
- Simulation starten: In einer Simulation werden historische Daten verwendet, um die Performance der Vorhersage zu simulieren. Die Anzahl der Zeilen auf denen simuliert kann unter „Trigger" → „Details anzeigen" eingestellt werden. Die Outputs werden dabei nicht befüllt – die Simulationsergebnisse werden stattdessen unten im rechten Bildschirmbereich angezeigt.
- Pipeline starten: Die Pipeline startet mit historischen Daten das Training und wechselt dann in den Live Modus.
- Mit historischen Daten starten: Die Pipeline startet mit historischen Daten und generiert für diese Outputs.
Hinweis: Die Optionen „Mit historischen Daten starten" und „Simulation starten" greifen beide auf den selben Datenblock zu (einzustellen unter „Trigger" → „Details anzeigen"). Die Simulation läuft schneller durch, als die Option "Mit historischen Daten starten".
Anwendungsfälle der Betriebsmodi
| Betriebsmodi | „Simulation starten" | „Pipeline starten" | „Mit historischen Daten starten" |
|---|---|---|---|
| Fragestellung | Kann mein Prozess modelliert werden? | Ich möchte meinen Prozess in Echtzeit modellieren. | Wie funktioniert der Datenfluss? |
| Datensatz | Maximale Zeilen für Simulation | Maximale Zeilen für Initialisierung + Echtzeit Daten | Maximale Zeilen für Simulation |
Trainingseinstellungen
Das Modell kann sich nach einer definierten Anzahl an Zeilen neu trainieren (anpassen) oder eine neue Architektursuche vornehmen (größere Anpassung). Dies kann über folgende Werte eingestellt werden:
- Intervall Training: Anzahl der Zeilen, nach denen ein Neutraining durchgeführt wird.
- Intervall Architektursuche: Anzahl der Zeilen, nach denen eine Architekturanpassung durchgeführt wird.
- Datensatzgröße: Anzahl der Zeilen, auf die das Modell sich trainieren darf.