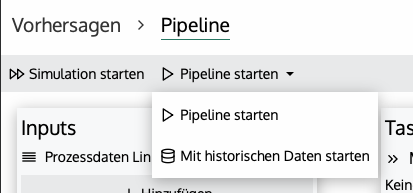
Betriebsmodi einer Pipeline
In der Übersicht einer Pipeline gibt es verschiedene Betriebsmodi:
- Simulation starten: In einer Simulation werden historische Daten verwendet, um die Performance der Vorhersage zu simulieren. Die Anzahl der Zeilen auf denen simuliert kann under Trigger / Details anzeigen eingestellt werden. Die Outputs werden nicht befüllt, im rechten Bildschirmbereich werden die Simulationsergebnisse angezeigt.
- Pipeline starten: Die Pipeline startet mit historischen Daten das Training und wechselt dann in den Live Modus.
- Mit historischen Daten starten: Die Pipeline startet mit historischen Daten und generiert für diese Outputs.
Die Optionen "Mit historischen Daten starten" und "Simulation starten" greifen beide auf den selben Datenblock zu (einzustellen unter Trigger / Details anzeigen). Die Simulation läuft schneller durch, als die Option "Mit historischen Daten starten".
Anwendungsfälle der Betriebsmodi
| Betriebsmodi | "Simulation starten" | "Pipeline starten" | "Mit historischen Daten starten" |
|---|---|---|---|
| Fragestellung | Kann mein Prozess modelliert werden? | Ich möchte meinen Prozess in Echtzeit modellieren. | Wie funktioniert der Datenfluss? |
| Datensatz | Maximale Zeilen für Simulation | Maximale Zeilen für Initialisierung + Echtzeit Daten | Maximale Zeilen für Simulation |
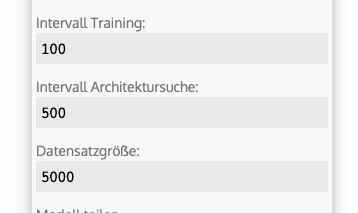
Trainingseinstellungen
Das Modell kann sich nach einer definierten Anzahl an Zeilen neu trainieren (anpassen) oder eine neue Architektursuche vornehmen (größere Anpassung). Dies kann über folgende Werte eingestellt werden:
- Intervall Training: Nach wie vielen Zeile ein Neutraining passieren darf.
- Intervall Architektursuche: Nach wie vielen Zeilen eine Architekturanpassung durchgeführt werden darf.
- Datensatzgröße: Auf wie vielen Zeilen das Modell sich trainieren darf.