Im Modul Predictions können Pipelines zur Produktionsprozessmodellierung angelegt werden. Jede Pipeline erstellt ein eigenes Modell, um von Input- auf Outputdaten zu schließen. Dabei kümmert sich die smartPLAZA um das Training (das initiale Anpassen des Modells auf den Prozess) und das spätere Ausführen des Modells (auch Inferenz genannt).
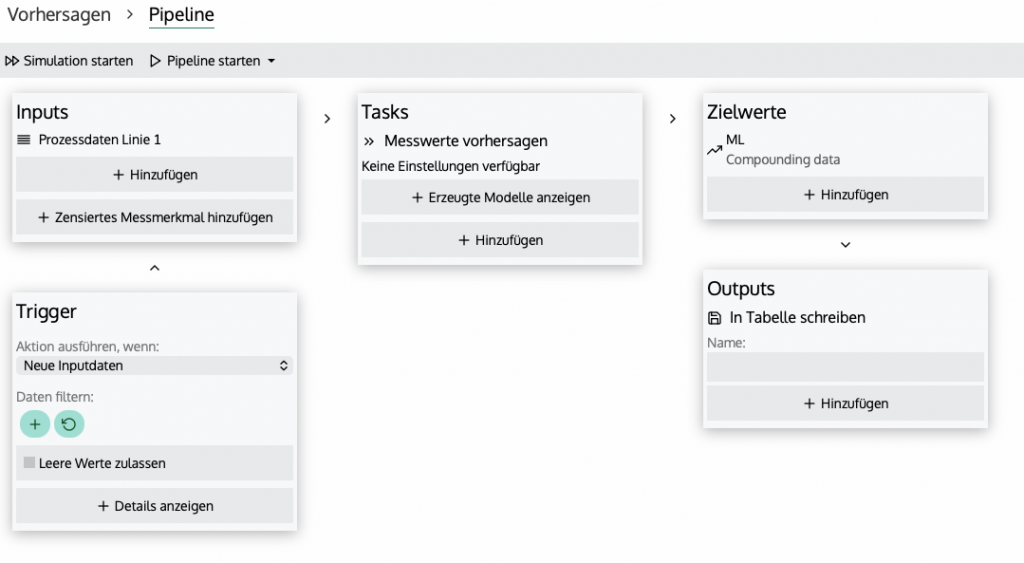
Komponenten einer Prediction Pipeline
Trigger
Der Trigger entscheidet, wann eine Pipeline ausgeführt und einen Zielwert vorhergesagt werden soll. Dies kann zum Beispiel sein, wenn neue Inputdaten weggeschrieben werden. Ebenfalls können die Input-Daten gefiltert werden, um zum Beispiel manche Artikel oder Anlagenzustände auszuschließen.
Ebenfalls kann definiert werden, wie viele Daten zum initialen Training und zur Simulation herangezogen werden.
Inputs
Hier werden die Tabellen für die Rohdaten definiert. Es können einzelne Messmerkmale ausgeschlossen werden.
Tasks
Tasks sind die Aufgaben einer Pipeline. Standardmäßig wird der Task "Messwerte vorhersagen" verwendet. Dieser bildet ein Regressionsmodell, um den Zielwert vorherzusagen.
Zielwerte
Zielwerte sind die Messmerkmale, die eine Pipeline modelliert. Es kann ein oder mehrere Messmerkmale als Zielwert definiert werden.
Outputs
Die Outputs geben an, was mit den Zielwerten passieren soll. Je nach gewähltem Output kann in eine DatenBerg interne Tabelle oder an externe Quellen wie eine API zurückgeschrieben werden.



